
|
Codages Principes psycho acoustiques Codeurs perceptuels Fourier MPEG - 1 MPEG - 2 PASC ATRAC Dolby AC apt-X 100 IMA ADPCM |
L'objectif principal de la compression de données est de conserver une qualité sonore maximum tout en réduisant le plus possible la taille des données. La compression de données fonctionne en supprimant l'information inutile ou redondante du flux de données, tout en préservant la qualité sonore. Réduction de données audio et reconstruction 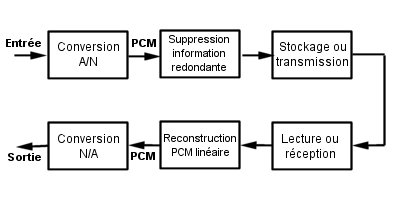 Généralement il faut choisir un compromis entre qualité et réduction de la taille des données. Codage avec ou sans pertes Deux types de codages sont possibles : Il est possible d'utiliser ce type de codage sur des données audio. Les données PCM d'origine vont ętre reproduites ŕ la perfection sans ajout de bruit. Mais la réduction des données est de l'ordre 2.5:1 (cela varie suivant l'information ŕ compresser). Męme si ce type de codage peut s'effectuer en temps réel, les taux de compression sont généralement insuffisants. Il est possible de parvenir ŕ des débits inférieurs ŕ 100 kbits/s par canal tout en conservant une bonne qualité sonore. En revanche pour un débit de 192 kbits/s la qualité atteinte rivalise avec le PCM d'origine.  Principes psycho acoustiques Le codage perceptuel est basé sur des notions de psycho acoustique (étude de la perception auditive). Un masquage intervient lorsqu'un son rend un autre (partiellement) inaudible. Une composante d'un son complexe peut masquer d'autres composantes plus discrčtes. Le masquage intervient ŕ la fois dans le domaine temporel et dans le domaine fréquentiel. L'effet de masque d'un son pur s'étend légčrement en dessous et au-dessus de sa propre fréquence en fonction de son niveau. Effet de masque sur un son pur ŕ 40 khz et 80 dB  Les sons situés au dessous de la courbe de masquage ne seront pas perçus normalement. Ils peuvent ętre "démasqué" par d'autres sons provenant de directions différentes (Gerson). L'effet de masque est maximum lorsque deux sons occupent la męme bande critique (Fletcher puis Zwicker) au sein du męme systčme. Les bandes critiques sont des bandes de fréquences distinctes (24 entre 20 Hz et 15 kHz) ŕ l'intérieur desquelles l'effet de masque est constant et indépendant de la séparation de fréquences entre son masquant et son masqué. Lorsque deux sons sont séparés en fréquence par plus d'une bande critique, l'effet de masque est réduit. Le masquage non simultané définit un masquage intervenant aprčs ou avant. Types de masques  En post masquage un son masque un autre son arrivé légčrement aprčs lui. En pré masquage, le masquage précčde le son (cas plus difficile ŕ montrer). Principes généraux des codeurs perceptuels Pour compresser du PCM linéaire, il existe deux moyens : Le codage perceptuel utilise le masquage qui permet d'accroître le niveau de bruit sans perte de qualité sonore. On considčre qu'un bruit de quantification est acceptable ŕ condition qu'il reste en dessous du seuil de masquage du signal audio concerné. Ce type de codeur travaille en divisant le signal audio en un certain nombre de bandes étroites, puis en requantifiant chaque bande ŕ une résolution inférieure en conformité avec le modčle psycho acoustique. Encodeur psycho acoustique ŕ basse résolution  La division en sous bandes peut ętre réalisée de deux façons : Bruit de quantification 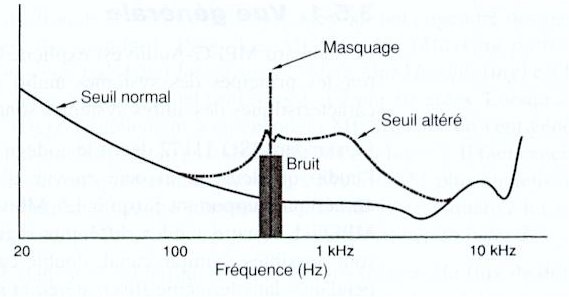 Le bruit situé dans la męme bande qu'une composante du signal peut ętre de trčs haut niveau tout en restant en dessous du seuil de masquage. Le codeur alloue un certain nombre de bits ŕ chaque bande mais attribue plus de bits aux bandes dont l'effet de masque est réduit. Si le masque est trop important il peut męme arriver que la bande ne soit pas codée. Le seuil de masquage est un seuil moyen par blocs. Dans le cas ou un bloc contient de l'audio ŕ un niveau trčs élevé suivi par de l'audio de trčs bas niveau, il peut arriver que le bruit, masqué par la premičre partie du signal se situe au-dessus du seuil de la seconde partie du signal.  Dans ce cas les effets de masquage "avant" et "aprčs" aident ŕ cacher les petites parties d'un bloc dont le bruit risque d'ętre audible. Il existe męme des systčmes ŕ allocation dynamique de longueur de bloc en fonction du contenu du signal. Les seuls systčmes de codage ŕ perte ŕ ne pas utiliser le codage perceptuel parviennent ŕ des résultats de l'ordre 4:1 comme taux de réduction. Ce sont l'apt-X 100 et le codage par prédiction linéaire (LPC). Transformation de Fourier L'organe de l'oreille interne qui nous permet de détecter la tonalité des sons que nous entendons s'appelle la cochlée. La cochlée transforme les variations de pression captées par le tympan en une information fréquentielle que le cerveau interprčte comme une tonalité et une texture. La transformée de Fourier est une technique mathématique qui réalise une tâche analogue. Transformée de Fourier La transformation de Fourier est due ŕ Fourier (mathématicien français) et repose sur le principe suivant : quasiment toutes les fonctions sont décomposables en une somme de cosinus et de sinus ŕ des fréquences différentes. Ce concept est omniprésent dans le traitement du signal. Ainsi, lorsque l'on représente une fonction dans un repčre Amplitude/Temps, la transformation de Fourier permet de la voir dans un repčre Amplitude/Fréquence. Cela permet d'obtenir les composantes en fréquence d'un signal.  x(t) : signal d'entrée (fonction du temps) f la fréquence i la base des nombres complexes De plus, on peut retrouver la fonction d'origine ŕ partir de la transformée de Fourier en appliquant la transformée de Fourier inverse. Généralement, si le bruit d'un signal est important, alors les composantes en hautes fréquences vont ętre importantes. Du coup il va ętre possible d'appliquer un filtre passe-bas sur le signal de façon ŕ restreindre au maximum l'effet du bruit. Mais la transformée de Fourier pose plusieurs problčmes : Transformée de Fourier rapide La transformée de Fourier discrčte est un algorithme qui convertit une fonction du temps ŕ valeurs complexes échantillonnées en une fonction ŕ valeurs complexes de la fréquence, également échantillonnée. Voici l'équation de la transformée de Fourier discrčte pour un signal de N échantillons : 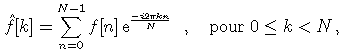 xkest le kičme nombre complexe en entrée (domaine temporel) yp est le pičme nombre complexe en sortie (domaine fréquentiel) n = 2N est le nombre total d'échantillons k et p sont dans l'intervalle 0 .. n-1. Mais cette formule demande n2 additions et multiplications complexes. Or, un calcul simple montre que les coefficients de fréquence paire sont ceux de la transformée de Fourier du signal n/2 périodique et que les coefficients de fréquence impaire sont ceux de la transformée de Fourier du signal En poussant le raisonnement par récurrence, on voit que le nombre d'opérations nécessaires au calcul de la transformée de Fourier par cette méthode est de l'ordre de KN log2(n), oů K est une constante indépendante de N. C'est le principe de base de la transformée de Fourier rapide. Plusieurs variantes en existent, toutes cherchant ŕ minimiser K. ISO - MPEG - 1 L'ISO (International Standarts Specifications) et l'IEC (International Electrotechnical Commission) ont trčs vite reconnu le rôle important de la compression dans le futur du multimédia. En 1988 ils ont établi le MPEG (Moving Pictures Extern Group) dans le but d'aboutir ŕ un standard international. La męme année l'audio au travers du MPEG-audio fut formé. Vue générale Le MPEG_1 audio dispose de quatre modes : La réduction des données audio comprend trois couches (layers) de complexité, du layer 1 au layer 3. Le layers de niveau élevé donnent de meilleurs résultats ŕ faibles débits mais entraînent des codages plus longs.
Le standard ISO ne définit que les formats du flux de données encodées ainsi que le processus de décodage, laissant ainsi le champ libre ŕ l'amélioration du modčle psycho acoustique utilisé. Mais le standard comporte des indications sur l'encodage et les modčles acoustiques pour aider au développement. Systčme d'encodage Les données sont initialement divisées pour tous les layers en 32 sous bandes par l'intermédiaire d'un filtre numérique. Une bande de filtrage additionnelle est employée en layer 3 de façon ŕ augmenter la précision jusqu'ŕ 275 bandes indépendantes, et un analyseur psycho acoustique différent est utilisé. MPEG-Audio Layer 1  En layer 1, des blocs de 384 échantillons PCM sont divisés en 32 sous-bandes, c'est ŕ dire qu'on obtient 12 échantillons par sous bandes. Ces échantillons sont ensuite échelonnés par rapport ŕ l'échantillon de plus haut niveau de chaque groupe de 12 échantillons. De cette façon, les bits les actifs sont placés sur les bits les plus significatifs (MSB), ce qui permet de requantifier linéairement selon le nombre de bots disponible en supprimant les LSB et en arrondissant adéquatement. Les bits sont attribués ŕ chaque sous bande suivant les besoins, c'est ŕ dire suivant le niveau de masquage souhaité. Chaque échantillon de sous bande se voit attribuer entre 0 et 15 bits. MPEG-Audio Layer 2  En layer 2 une économie supplémentaire est réalisée car les données d'échantillons, les facteurs d'échelle, ainsi que l'information d'allocation des bits sont groupés de façon ŕ ce qu'ils puissent ętre utilisés ŕ plus d'un seul groupe de 12 échantillons de sous bande. MPEG-Audio Layer 3  L'apport en complexité du layer 3 est énorme. Le layer 3 utilise : Format de trame  La trame est constituée : Dans chaque trame les données audio comprennent des informations d'allocation des bits, des informations de facteur d'échelle et des données d'échantillon de sous bande. Les données d'allocation des bits indiquent combien de bits ont été attribués par échantillon pour chaque sous bande Le facteur d'échelle (6 bits) indique le facteur par lequel les échantillons requantifiés doivent ętre multipliés au décodage afin de reconstruire les bons niveaux. La trame du layer 2 représentent trois fois le nombre d'échantillons PCM contenus dans une trame du layer 1, mais pas forcément le nombre de facteurs d'échelle ou de valeurs de l'échantillon audio. Du coup la trame doit contenir une information qui indique le nombre de facteurs d'échelle inclus pour chaque bande. Décodage Le décodage s'effectue en sens inverse de celui d'encodage, mais sans passer par le modčle psycho acoustique. Codage en stéréo jointe Il faut nécessairement que les paires de signaux stéréo possčdent des redondances. Il existe deux méthodes : ISO - MPEG - 2 L'objectif de la norme MPEG-2 est d'introduire des améliorations tout en restant compatible avec le standard ISO. Contrôle de la plage dynamique Dans les layers 1 et 2 du MPEG-2 ont été intégré un contrôle de la plage dynamique, c'est ŕ dire que la compression s'adapte ŕ la plage dynamique d'environnement de l'utilisateur final. Pour cela il faut multiplier les facteurs d'échelle par un facteur de gain approprié, associé ŕ des constantes de temps adéquates de façon ŕ éviter les effets secondaires. Son multicanal La difficulté est de préserver la compatibilité avec les décodeurs MPEG-1. L'option surround permet la transmission de 5 canaux discrets en réduction de données, tout en utilisant une matrice de compatibilité qui autorise la transmission des canaux de bases Gauche / Droite sur la partie visibles par les décodeurs MPEG-1. Matrice de compatibilité de l'extension multicanal MPEG-2  L'extension multicanal comporte aussi des canaux multilingues ou infra-basses. Basses fréquences d'échantillonnage L'objectif principal du MPEG-2 a été d'étendre le standard ISO ŕ des taux de transfert et d'échantillonnage inférieurs de façon ŕ obtenir une qualité audio raisonnable pour les applications multimédias tout en exploitant des débits allant de 24 ŕ 64 kbits/s. Trois nouvelles fréquences d'échantillonnage sont apparues : 24, 22.05 et 16 kHz (la moitié des précédentes). L'utilisation de fréquences plus basses permet des sous bandes plus étroites et donc un meilleur contrôle du bruit de quantification. PASC Le Precision Adaptative Sub-band Coding (PASC) a été conçue par Philips pour sa DCC (Digital Compact Cassette). L'algorithme PASC effectue deux tâches distinctes : L'algorithme PASC atteint des taux de compression de 4:1. De plus son rôle filtreur élimine tout ou partie des bruits résiduels. ATRAC L'Adaptive Transform Acoustic Coding (ATRAC, codage par transformation acoustique adaptive) est le systčme mis en oeuvre par Sony pour son Minidisc ainsi que pour son cinéma multicanal SDDS (Sony Dynamic Digital Sound). L'ATRAC apporte une réduction des données de l'ordre de 5:1. La particularité du systčme ATRAC est de posséder un algorithme évolutif; depuis sa création en 1992, celui-ci s'est amélioré au fil de ses différentes versions et la qualité de reproduction n'a donc cessé d'augmenter depuis la version 1.0.
L'algorithme ne travaille plus avec des convertisseurs A/N conventionnels mais avec une plus haute résolution. Le format 24 bits est aujourd'hui adopté par Sony, ce qui permet de réduire le niveau de bruit de maničre considérable ainsi que de travailler avec une plus grande précision de retour en 16 bits. Le résultat est que, męme dans les bas niveaux (-80 dB), le systčme est capable de reproduire le son enregistré sans pour autant générer le bruit de quantification du 16 bits classique. Ce qui veut dire qu'un niveau de -80 dB provenant d'un MiniDisc possčde une qualité sonore bien supérieure au -80 dB d'un CD. L'encodeur comporte trois éléments : Le débit ŕ l'entrée de l'encodeur est celui du CD, c'est-ŕ-dire 1,4 Mbits / sec tandis qu'ŕ sa sortie il est de 292 kbits / sec, soit une compression d'environ 5 : 1. Dolby AC-1, AC-2 et AC-3 Le Comité ATSC (Advanced Television Systems Comitee) est une organisation internationale qui comprend 200 membres et qui détermine les standards pour la télévision haute qualité. L'ATSC a par exemple défini les standards de la télévision haute définition (HDTV), les standards de la télévision (SDTV), de transmission télévisuelle, du son surround multicanal, et de la diffusion satellite. L'ATSC est l'organisme qui a validé l'AC-3. L'AC-1 est le procédé adaptatif ŕ modulation delta développé par Dolby au milieu des années 80 (débit supérieur ŕ 200 kbits/q par canal). L'AC-3 est la seconde génération d'algorithmes de codage ŕ faible débit de Dolby. Il en existe deux encodeurs : L'AC-3 (1992) intervient dans le codage multicanal du systčme Dolby SR-D et du Home cinéma (DVD). Ce procédé exploite les redondances entre canaux, et réduit le taux de données des facteurs d'échelles. L'AC-3 est souvent appelé Dolby Digital 5.1, les six canaux discrets sont Gauche, Centre, Droite, AR-Gauche, AR-Droit et le caisson de basses (inférieur ŕ 120Hz). Souvent confondu, l'AC-3 est un algorithme de compression, assimilé au 5.1, mais il est aussi employé pour encoder de l'audio en d'autres formats ( mono 1.0, stereo 2.0, etc...). L'apt-X 100 L'apt-X 100 a été développé par Audio Processing Technology, une filiale de Solid State Logic. C'est un systčme qui ne repose pas ŕ la base sur l'effet de masque. Mais il n'est performant que lorsque la théorie du masquage est appliquée ŕ l'analyse du bruit. Il est fondé sur le codage de la voix mais vise aussi les application smusicales de haut niveau. Il divise le signal audio en 4 bandes seulement, et accompli sa réduction en fonction du débit en utilisant la prédiction linéaire et la modulation par impulsions codées adaptative (on enregistre les variations entre les valeurs et non pas les valeurs elles-męmes). Pour une fréquence d'échantillonnage de 32 kHz, le débit résultant est de 128 kbits/s par canal, et de 192 kbits/s ŕ 48 kHz. IMA ADPCM L'International Multimedia Association (IMA) s'est chargé d'établir un degré de standardisation des divers atériaux multimédias. Elle a définit l'algorithme AMA ADPCM (fondé sur l'algorithme Intel/DVI) qui autorise un décodage en temps réel par l'unité centrale de l'ordinateur sans ressources additionnelles autres qu'un logiciel de décompression (contrairement aux standarts MPEG). Il permet d'encoder de l'audio 16 bits de haute qualité vers du 4 bits par échantillon en utilisant une forme de PCM différentiel : la valeur de l'échantillon suivant est calculé ŕ partir de l'échantillon actuel. Une quantification ŕ 4 bits ŕ intervalle variable, dépendant du taux de variation de la forme d'onde est appliqué. Au décodage, le mécanisme est inversé. Le gain de ce systčme de compression est de 4:1 pour un temps de décompression rapide. |
||||||||||||||||||||||||||||||||||||||||||||||||||||